Voxel渲染器开发(1) | 从体素游戏到稀疏体素八叉树
大概没有游戏玩家不知道Minecraft这款游戏。
在如今似乎一个游戏只要用了大量的方块就常常用类Minecraft游戏指代,方块元素有着极高的辨识度。但今天来聊聊虽然也是方块但还是有些不大一样的体素游戏。
什么是体素?
用一句话概括:体素(Voxel)是3D版本的像素(Pixel)。
狭义上定义的体素风格渲染:每个Voxel应该和pixel一样都是相同的颜色,而不是Minecraft中的方块有对应的Texture。所以严格意义上来讲MC并不是一个体素游戏,但似乎体素游戏也没法区分得特别严格。像很多低多边形(LowPoly)模型建模的游戏也都使用了体素这样形式的3D模型,而其他的部分和普通3D游戏并没有太大区别。从我个人的角度来看,除了所有体素使用单一颜色的标准之外,大部分的游戏模型以及地形、建筑、物体都要是在体素网格上对齐,而没有旋转和缩放的才能称作是体素游戏。
最早接触的体素游戏大概就是CubeWorld了。CubeWorld在2013年刚刚发布测试版本的时候,就被这种比MC更细致颗粒度的Voxel渲染惊艳到了。

当然后来的模拟经营游戏StoneHearth也很吸引人,不过开发者半路弃坑了。

似乎体素风格的游戏都能自带热度。2020年底的爆款游戏Teardown,大量的模型细节和巨大的体素场景,可以自由交互的体素物理系统,简直满足了破坏类沙盒玩家无尽的幻想。游戏不应该都是可破坏的吗(这里赞一下EA的战地建筑破坏效果)。当然构建这样一个Voxel World并不是一件简单的事情,随意破坏后的大规模体素对象的碰撞,刚体、软体模拟有着巨大的开发工作量。

体素游戏的渲染方式
如果要说渲染优化的话,Teardown还是传统的PolygonMesh的方式。即将体素模型和信息先转化为polygon mesh再进行传统渲染管线渲染。所以Teardown的技术难点更多的是在于其物理引擎的实现而不是渲染,当然这次我们只来聊体素的渲染。
Teardown的开发过程中使用的体素建模工具是MagicaVoxel,也是目前市面上几乎唯一可以用于商业化游戏的体素编辑软件了。
MagicaVoxel由独立开发者ephtracy从2015年发布一直维护更新到现在。对于这种软件应用来说,体素由于其简单的立方体结构和排列方式比起三角面来说更适合进行光线追踪,可以做影视级别的真实渲染。所以在支持实时渲染的动态编辑同时它还支持光线追踪渲染高质量的画面。这次我们就尝试复刻下MagicaVoxel的光线追踪渲染器。是的,Flag立下了!
不过随着光追显卡的不断普及和技术发展,我们可能会在未来的几年内看到全局RayTracing的体素游戏。但体素风格始终是个小众的游戏美术风格,对独立游戏开发者来说,不需要太大的美术制作成本,体素风格始终是一个可选美术方案。

这里总结一下Voxel的渲染方式
- 传统PolygonMesh:游戏常见做法
- 光线追踪:数字内容制作软件,影视及图形学科研
除去体素本身作为模型数据替代Mesh进行绘制,在游戏渲染中体素化方案也可以用来实现全局光照。体素化场景提供了简化的3D spacial info,基于这个信息进行粗糙的光照传播和计算。例如 LPV(Light Propagation Volumes) 和Nvidia的VXGI(Voxel Global Illumination)。
和Voxel Rendering 不同,全局光照中的Voxel信息通常存储在3D texture,贴图分辨率低。同时体素化是对于相机视锥体(Frustum)的,这里的voxel是广义的体素,是个长方体。在投影变换之前是个四棱台(Four Prism),在图形学中有个专有的名称Froxel(Frustum+Voxel)。后续有机会我们再来讲VXGI。

这两种渲染方式各有优劣同时还决定了体素数据的储存。
三种体素数据的存储方式
- 多边形网格
- 3D Texture
- 八叉树结构
多边形网格的储存就不用多说了,不过相对于常见的Mesh,体素Mesh的顶点数量相对庞大,同时不需要UV数据和贴图采样,每个体素的颜色可以存储在顶点颜色中。在实际渲染里通常会有优化算法将相同材质的顶点合并。
光线追踪的渲染方式,体素数据的存储就有多种方案了。我们可以直接储存在3D贴图中采样,和每个体素的包围盒进行光线的相交判定。也可以使用空间划分加速结构,储存在八叉树结构中,更快速找到体素模型和光线最近的交点。
稀疏体素八叉树(Sparse Voxel Octree)
将一个三维空间划分为八个子空间,不断细分下去直到每一个空间对应一个体素单元,存储上填充信息。当一个空间中没有填充的变化即全部填充或全部不填充时,不再细分存储数据,就可以得到一个稀疏的体素八叉树,将这些八叉树细分的Box绘制出来大概就长这样。

八叉树结构对比3D贴图的优势在于,对于空间中的空洞区域,八叉树结构是稀疏的不占用内存的空间。而3D贴图即使是大范围的空洞我们也需要预先分配存储空间。
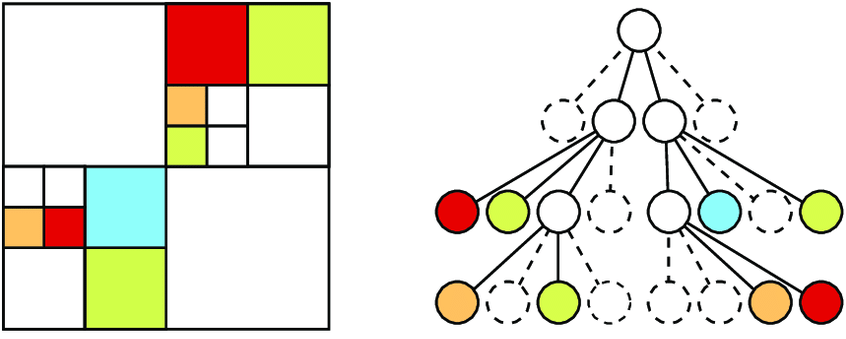
从不同的角度对比稀疏体素八叉树和其他的数据模型。体素这种细节粒度细致的模型,就特别需要LOD系统来减少渲染的绘制开销。多边形网格的LOD实现要维护多套不同层级的Mesh。3D Texture采样的数据,LOD自然就是采样不同层级的Mipmap。而对于八叉树结构来说LOD采样同样直观,我们只需要减少Octree遍历的层级就可以实现八叉树的LOD。
同时体素数据不只是二值数据,还包含了材质信息。如果使用PBR渲染,我们需要储存包括体素颜色,粗糙度Roughness和金属度Metallic,以及自发光信息Emission。
对于多边形网格来说,这些数据可以直接存储在顶点数据中。而3D Texture的储存空间有限,ARGB32 只能存4个unorm,而刚才我们提到的参数有3+1+1+1=6个unorm。如果还要再考虑半透明材质的话就需要更多的空间存储。
八叉树的数据结构在GPU中实现时,是一个一维结构体数组,可以支持数据的扩展。
那么对于3D贴图有没有其他的方案呢?当然!类似于Deferred Texturing方案 我们可以只存储一个Material ID,再从材质数据的数组中查找对应的材质参数。这样我们就能获得理论上无限的Per Voxel数据空间。而且这个方案三种储存方式都可以使用。
总之体素八叉树是一个有较多优点的Voxel存储方案,由于空间大部分都是稀疏的没有体素填充,八叉树的存储空间会更小。
SparseVoxelOctree的实现
我们很容易就可以定义一个SVO的节点:
1 | public class SVONode |
- 8个节点按照x,y,z轴顺序从0-7进行索引。
- child_valid 8个bit标识8个子voxel是否有数据,如果子节点没有再细分,对应的bit置为0。
- child_fill 标记当对应索引的子voxel child_valid为0时的填充状态。
- Volume 储存了每个节点的包围盒大小,方便后续的计算
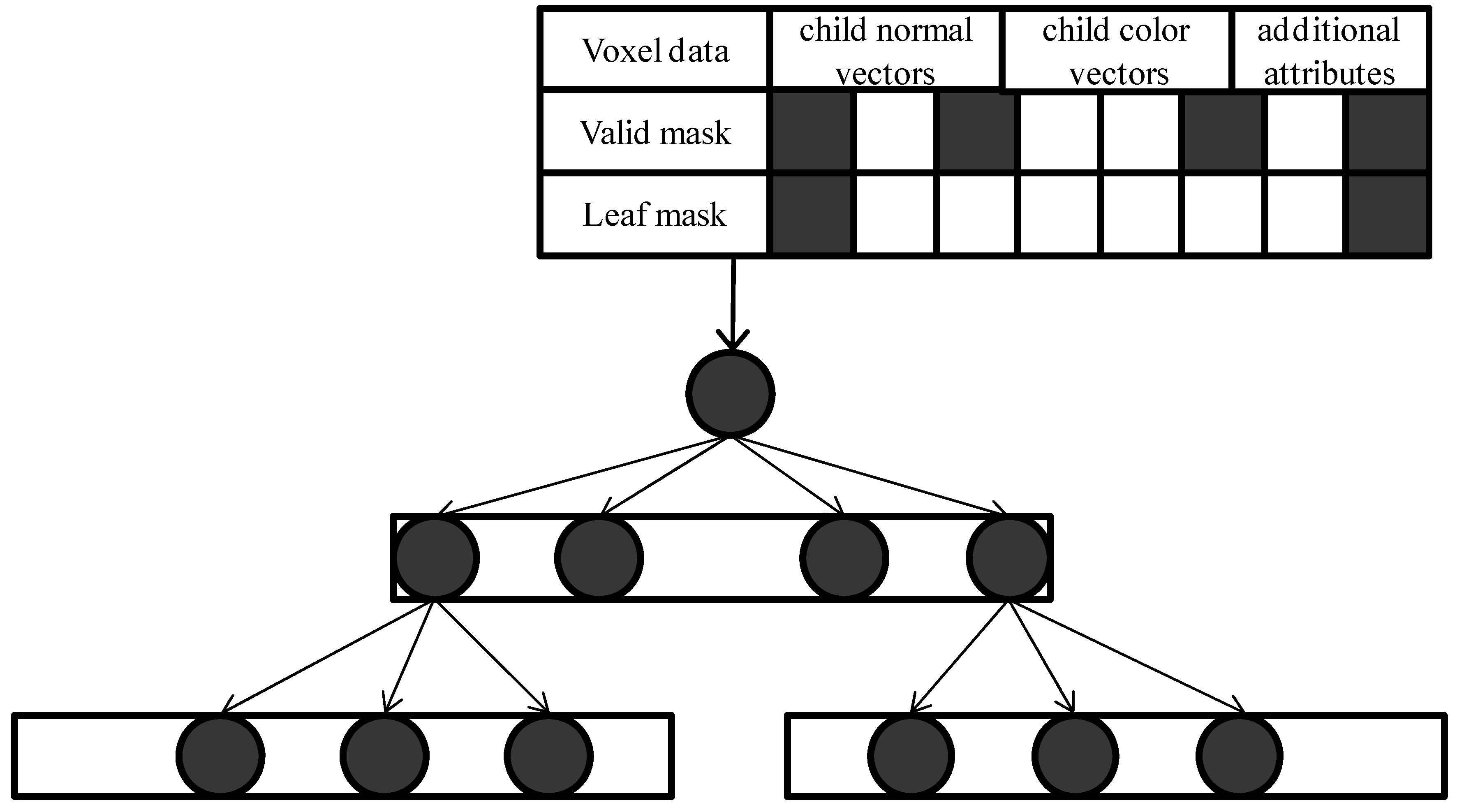
用两个byte来储存叶节点的填充信息可以减少一个层级的数据储存节省空间。到目前为止,我们暂时还不考虑材质信息的存储。对于CPU的SVO实现,数据的内存排布自由度更大。等后续我们讲到GPU实现的SVO再来考虑。
定义完SVO的结构,我们再来实现一下SVO的遍历算法。对于实现光线追踪渲染器来说,最重要的算法就是射线和SVO的相交计算。我们可以先从最简单的一个Voxel和射线相交计算开始。只要解决了这样一个Primitive问题,整个复杂的SVO结构就是大大小小嵌套的Voxel和Ray的计算。
射线和Voxel相交
Voxel等价于一个长宽高都相同,退化的Box。在Inigo Quilez(也被称为iq大神,ShaderToy网站的创始人)的Blog里给出了一系列射线和集合体相交的算法。相交函数返回了一个float2分别表示近相交点和远相交点到射线原点origin的距离t。如果Box和Ray没有相交那么返回-1.0。
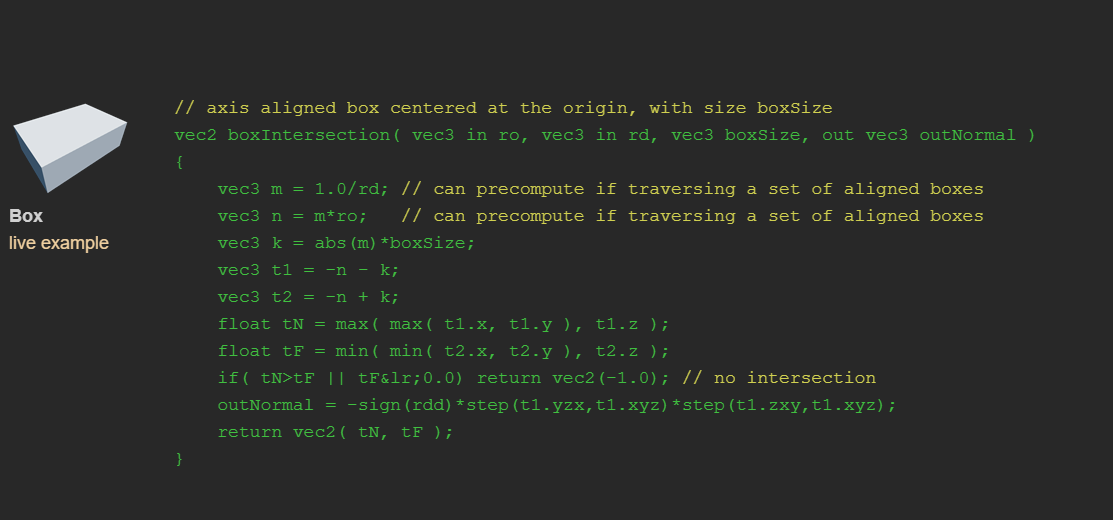
如果这个算法看不懂也没有关系,在《Real-Time Rendering Fourth Edition》中的第22.7章节,一个图可以直观解释这个算法的原理。
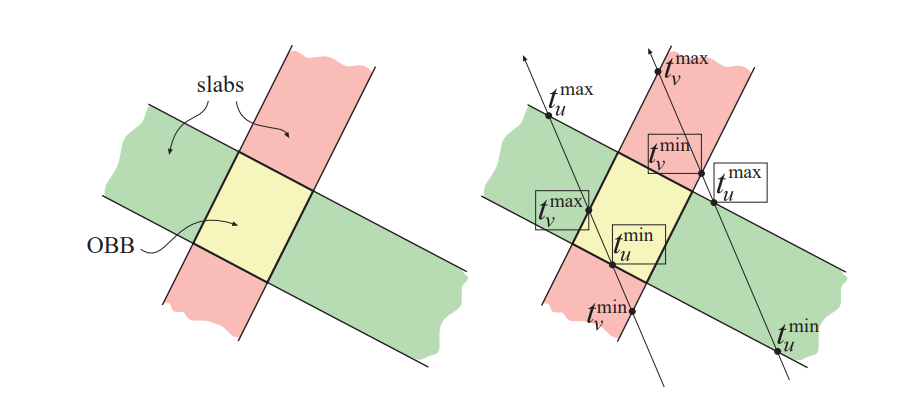
对于一个不与坐标轴平行(Axis-Aligned)的Box来说,我们可以考虑射线将Box与坐标轴对齐,同时还可以平移整个坐标系,把Box的中心放在原点。这样我们就只需要考虑简化版本的相交情况。
我们可以定义一条射线的解析形式为:
- o 为射线的原点origin
- d 为射线的方向向量
- 同时Box的半边长为(x,y,z),对于Voxel来说x=y=z。
这样我们就可以很好求得射线与Box的两个交点和射线原点的距离、。
先设定X轴方向上的相交的距离、。
同理可以计算出 、、、。
那么实际和Box相交的距离t就在这六个中间。经过简单的观察,射线最终的近交点是每个坐标轴的较近交点距离最远的,远交点为每个坐标轴远交点距离最近的。
我们可以先计算坐标轴上的近交点和远交点分别为,。(由于d是个方向向量可能为负值,Box的半边长x一定是正值,没法直接比较和的大小)
那么整个Box和射线最终的两个交点公式就是:
1 | t_min = max(tx_min,ty_min,tz_min) |
所以Inigo Quilez给出的算法中有个abs方法能够方便找到哪个t是或。当然我们还可以简化该算法,即如果射线方向的某个坐标轴方向是负值,我们将整个坐标轴翻转,翻转并不影响计算相交的距离。这样我们就可以避免了判断和,等后续我们讲到GPU的计算优化时还会提到。
遍历整个体素八叉树
有了RayBox的相交函数我们就可以来递归调用整个SVO的相交了。
简单叙述下逻辑:
对于一个Voxel,先判断是否与射线相交:
- 不相交:返回-1
- 相交:遍历子Voxel,找到最近的相交子节点,返回距离t
- 如果子Voxel是叶节点:
- 判断子Voxel是否填充,在填充的情况下计算其Box与射线的交点距离
- 如果子Voxel还包含更小的Voxel:
- 递归调用本身
- 如果子Voxel是叶节点:
写成代码就是下面的形式(是的我不想详细解释了直接上代码)
1 | private float2 TraversalBruteForce(float3 rpos,float3 rdir,ref float3 nor) |
最后,在Unity中,一个323232 SVO中的某个体素被填充后的可视化的样子。

下一篇我们来讲如何将SVO的数据结构和算法移植到Shader中,使用GPU进行渲染。